sábado, 22 de agosto de 2020
Restricciones
Restricciones
· Restricción de dominio: El valor de cada atributo A debe ser un valor atómico del dominio dom(A).
· Restricción de clave: Dos tuplas no pueden tener la misma clave.
· Integridad de la entidad: Ningún atributo que forme parte de la clave primaria de una relación puede tomar un valor nulo.
· Integridad referencial: Si una relación R2 (relación que referencia) tiene un descriptor que es la clave primaria de la relacin R1 (relación referenciada), todo valor de dicho descriptor debe concordar con un valor de la clave primaria de R1 o ser nulo. El descriptor es una clave ajena o foránea de la relación R2.
restricción de integridad referencialen el Entity Data Model (EDM) es similar a una restricción de integridad referencial en una base de datos relacional. Del mismo modo que una columna (o columnas) de una tabla de base de datos puede hacer referencia a la clave principal de otra tabla, una propiedad(o propiedades) de un tipo de entidad puede hacer referencia a la clave de entidad de otro tipo de entidad. El tipo de entidad al que se hace referencia se denomina extremo principal de la restricción. El tipo de entidad que hace referencia al extremo principal se denomina extremo dependiente de la restricción.
Una restricción de integridad referencial se define como parte de una Asociaciónentre dos tipos de entidad. La definición para una restricción de integridad referencial especifica la siguiente información:
El extremo principal de la restricción. Es un tipo de entidad a cuya clave de entidad hace referencia el extremo dependiente.
La clave de entidad del extremo principal.
El extremo dependiente de la restricción. Es un tipo de entidad que tiene una o varias propiedades que hacen referencia a la clave de entidad del extremo principal.
La propiedad o propiedades que hacen la referencia del extremo dependiente.
El propósito de las restricciones de integridad referencial de EDM es garantizar la existencia de asociaciones válidas..
Ejemplo
El diagrama siguiente muestra un modelo conceptual con dos asociaciones: WrittenBy y PublishedBy. El tipo de entidad Booktiene una propiedad, PublisherId, que hace referencia a la clave de entidad del tipo de entidad Publisher cuando se define una restricción de integridad referencial en la asociación PublishedBy.

El Entity framework Ado.Net usa un lenguaje específico de dominio (DSL) denominado lenguaje de definición de esquemas conceptuales (CSDL) para definir los modelos conceptuales. El código CSDL siguiente define una restricción de integridad referencial en la asociación PublishedBy mostrada en el modelo conceptual anteriormente citado.
Integridad referencial
La integridad referencial es propiedad de la base de datos. La misma significa que la clave externa de una tabla de referencia siempre debe aludir a una fila válida de la tabla a la que se haga referencia. La integridad referencial garantiza que la relación entre dos tablas permanezca sincronizada durante las operaciones de actualización y eliminación.Entre dos tablas de cualquier base de datos relacional pueden haber dos tipos de relaciones, relaciones uno a uno y relaciones uno a muchos:
Entre dos tablas de cualquier base de datos relacional pueden haber dos tipos de relaciones, relaciones uno a uno y relaciones uno a muchos:Relación Uno a Uno: Cuando un registro de una tabla sólo puede estar relacionado con un único registro de la otra tabla y viceversa. |
 |
Relación Varios a Varios: Cuandoun registro de una tabla puede estar relacionado con más de un registro de la otra tabla y viceversa. En este caso las dos tablas no pueden estar relacionadas directamente, se tiene que añadir una tabla entre las dos que incluya los pares de valores relacionados entre sí. Por ejemplo: tenemos dos tablas una con los datos de clientes y otra con los artículos que se venden en la empresa, un cliente podrá realizar un pedido con varios artículos, y un artículo podrá ser vendido a más de un cliente.No se puede definir entre clientes y artículos, hace falta otra tabla (por ejemplo una tabla de pedidos) relacionada con clientes y con artículos. La tabla pedidos estará relacionada con cliente por una relación uno a muchos y también estará relacionada con artículos por un relación uno a muchos. |
 |
Integridad,referencial |
Cuando se define una columna como clave foránea, las filas de la tabla pueden contener en esa columna o bien el valor nulo (ningún valor), o bien un valor que existe en la otra tabla, un error sería asignar a un habitante una población que no está en la tabla de poblaciones. Eso es lo que se denomina integridad referencial y consiste en que los datos que referencian otros (claves foráneas) deben ser correctos. La integridad referencial hace que el sistema gestor de la base de datos se asegure de que no hayan en las claves foráneas valores que no estén en la tabla principal. La integridad referencial se activa en cuanto creamos una clave foráneay a partir de ese momento se comprueba cada vez que se modifiquen datos que puedan alterarla. ¿ Cuándo se pueden producir errores en los datos? Cuando insertamos una nueva fila en la tabla secundaria y el valor de la clave foránea no existe en la tabla principal. insertamos un nuevo habitante y en la columna poblacionescribimos un código de poblacion que no está en la tabla de poblaciones (una población que no existe).Cuando modificamos el valor de la clave principal de un registro que tiene 'hijos', modificamos el codigo de Valencia, sustituimos el valor que tenía (1) por un nuevo valor (10), si Valencia tenía habitantes asignados, qué pasa con esos habitantes, no pueden seguir teniendo el codigo de población 1 porque la población 1 ya no existe, en este caso hay dos alternativas, no dejar cambiar el codigo de Valencia o bien cambiar el codigo de población de todos los habitantes de Valencia y asignarles el código 10.Cuando modificamos el valor de la clave foránea, el nuevo valor debe existir en la tabla principal. Por ejemplo cambiamos la población de un habitante, tenía asignada la población 1 (porque estaba empadronado en valencia) y ahora se le asigna la población 2 porque cambia de lugar de residencia. La población 2 debe existir en la tabla de poblaciones. Cuando queremos borrar una fila de la tabla principal y ese registro tiene 'hijos', por ejemplo queremos borrar la población 1 (Valencia) si existen habitantes asignados a la población 1, estos no se pueden quedar con el valor 1 en la columna población porque tendrían asignada una población que no existe. En este caso tenemos dos alternativas, no dejar borrar la población 1 de la tabla de poblaciones, o bien borrarla y poner a valor nulo el campo poblacion de todos sus 'hijos'. Asociada a la integridad referencial están los conceptos de actualizar los registros en cascada y eliminar registros en cascada |
El actualizar y/o eliminar registros en cascada, son opciones que se definen cuando definimos la clave foránea y que le indican al sistema gestor qué hacer en los casos comentados en el punto anterior. Actualizar registros en cascada: Esta opción le indica al sistema gestor de la base de datos que cuando se cambie un valor del campo clave de la tabla principal, automáticamente cambiará el valor de la clave foránea de los registros relacionados en la tabla secundaria. Por ejemplo, si cambiamos en la tabla de poblaciones (la tabla principal) el valor 1 por el valor 10 en el campo codigo (la clave principal), automáticamente se actualizan todos los habitantes (en la tabla secundaria) que tienen el valor 1 en el campo poblacion (en la clave ajena) dejando 10 en vez de 1. Si no se tiene definida esta opción, no se puede cambiar los valores de la clave principal de la tabla principal. En este caso, si intentamos cambiar el valor 1 del codigo de la tabla de poblaciones , no se produce el cambio y el sistema nos devuelve un error o un mensaje que los registros no se han podido modificar por infracciones de clave. Esta opción le indica al sistema gestor de la base de datos que cuando se elimina un registro de la tabla principal automáticamente se borran también los registros relacionados en la tabla secundaria. Por ejemplo: Si borramos la población Onteniente en la tabla de poblaciones, automáticamente todos los habitantes de Onteniente se borrarán de la tabla de habitantes. Si no se tiene definida esta opción, no se pueden borrar registros de la tabla principal si estos tienen registros relacionados en la tabla secundaria. En este caso, si intentamos borrar la población Onteniente, no se produce el borrado y el sistema nos devuelve un error o un mensaje que los registros no se han podido eliminar por infracciones de clave. |
jueves, 20 de agosto de 2020
Unidad diseño manejo y exploración de base de datos
1.1 MODELOS DE BASES DE DATOS
Un modelo de datos es básicamente una "descripción" de algo conocido como contenedor de datos (algo en donde se guarda la información), así como de los métodos para almacenar y recuperar información de esos contenedores. Los modelos de datos no son cosas físicas: son abstracciones que permiten la implementación de un sistema eficiente de base de datos; por lo general se refieren a algoritmos, y conceptos matemáticos.
Algunos modelos con frecuencia utilizados en las bases de datos:

En este modelo los datos se organizan en una forma similar a un árbol (visto al revés), en donde un nodo padre de información puede tener varios hijos. El nodo que no tiene padres es llamado raíz, y a los nodos que no tienen hijos se los conoce como hojas.
Las bases de datos jerárquicas son especialmente útiles en el caso de aplicaciones que manejan un gran volumen de información y datos muy compartidos permitiendo crear estructuras estables y de gran rendimiento.
Una de las principales limitaciones de este modelo es su incapacidad de representar eficientemente la redundancia de datos.
Base de datos de red:

Éste es un modelo ligeramente distinto del jerárquico; su diferencia fundamental es la modificación del concepto de nodo: se permite que un mismo nodo tenga varios padres (posibilidad no permitida en el modelo jerárquico).
Fue una gran mejora con respecto al modelo jerárquico, ya que ofrecía una solución eficiente al problema de redundancia de datos; pero, aun así, la dificultad que significa administrar la información en una base de datos de red ha significado que sea un modelo utilizado en su mayoría por programadores más que por usuarios finales.
Bases de datos transaccionales
Son bases de datos cuyo único fin es el envío y recepción de datos a grandes velocidades, estas bases son muy poco comunes y están dirigidas por lo general al entorno de análisis de calidad, datos de producción e industrial, es importante entender que su fin único es recolectar y recuperar los datos a la mayor velocidad posible, por lo tanto la redundancia y duplicación de información no es un problema como con las demás bases de datos, por lo general para poderlas aprovechar al máximo permiten algún tipo de conectividad a bases de datos relacional.
Bases de datos relacionales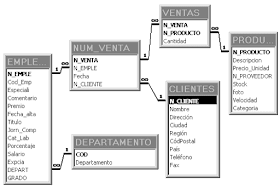
Estés el modelo utilizado en la actualidad para modelar problemas reales y administrar datos dinámica mente. Tras ser postulados sus fundamentos en 1970 por Edgar Frank Codd, de los laboratorios IBM en San José (California), no tardó en consolidarse como un nuevo paradigma en los modelos de base de datos. Su idea fundamental es el uso de "relaciones". Estas relaciones podrían considerarse en forma lógica como conjuntos de datos llamados "tuplas". Pese a que ésta es la teoría de las bases de datos relacionales creadas por Codd, la mayoría de las veces se conceptualiza de una manera más fácil de imaginar. Esto es pensando en cada relación como si fuese una tabla que está compuesta por registros (las filas de una tabla), que representarían las tuplas, y campos (las columnas de una tabla).
En este modelo, el lugar y la forma en que se almacenen los datos no tienen relevancia (a diferencia de otros modelos como el jerárquico y el de red). Esto tiene la considerable ventaja de que es más fácil de entender y de utilizar para un usuario esporádico de la base de datos. La información puede ser recuperada o almacenada mediante "consultas" que ofrecen una amplia flexibilidad y poder para administrar la información.
El lenguaje más habitual para construir las consultas a bases de datos relacionales es SQL, Structured Query Language o Lenguaje Estructurado de Consultas, un estándar implementado por los principales motores o sistemas de gestión de bases de datos relacionales.
1.2 CONSIDERACIONES DE DISEÑO

Una Base de Datos sirve para guardar datos en ella y para procesar dichos datos. El resultado de ese proceso se llama INFORMACIÓN.
DATOS —> PROCESO —> INFORMACIÓN
Los usuarios ingresan los DATOS en las tablas, en los stored procederes y en los triggers se PROCESAN esos datos, y el resultado de ese procesamiento es la INFORMACIÓN que se obtiene.
Para que la INFORMACIÓN sirva debe ser exacta, oportuna y confiable. Esto solamente puede conseguirse si los DATOS introducidos son exactos y si el PROCESO al que son sometidos es correcto. Si cualquiera de ellos (datos o proceso) está mal entonces es seguro que la INFORMACIÓN estará mal.
La introducción de los DATOS corre por cuenta y es responsabilidad de los usuarios.
El PROCESAMIENTO y la INFORMACIÓN corren por cuenta y es responsabilidad del diseñador de la Base de Datos.
Si un DATO es incorrecto, fue mal introducido, parte de la culpa puede ser del usuario y la otra parte de la culpa puede ser del diseñador de la Base de Datos.
Para evitar o al menos disminuir grandemente la posibilidad de que un usuario introduzca datos erróneos el Firebird nos provee de varias herramientas: restricción Foreign Key, restricción Ónique Key, restricción Check, dominios, triggers.
Mediante la restricción Foreign Key nos aseguramos que en una columna solamente se puedan guardar valores que existen en otra tabla. Si no existen en la otra tabla, no se grabarán.
Mediante la restricción Unique Key nos aseguramos que en una columna no haya datos repetidos. Ni duplicados, ni triplicados, ni nada de eso. Solamente datos únicos.
Mediante la restricción Check nos aseguramos que en una columna (o serie de columnas) solamente se puedan introducir valores que cumplen con las condiciones impuestas.
Mediante los dominios nos aseguramos que los valores de una columna sean solamente los permitidos.
Mediante los triggers nos aseguramos que antes de insertar o actualizar una fila los valores de sus columnas sean valores permitidos.
Si los DATOS o el PROCESO son incorrectos entonces lo que se obtiene no sirve, en otras palabras se obtiene basura, porque DATOS correctos utilizados por un PROCESO incorrecto da como resultado basura y DATOS incorrectos utilizados por un PROCESO correcto también dan por resultado basura.
Un “dato” es lo que se guarda, una “información” es lo que se obtiene después de “procesar” a los “datos”.
Siempre por el final, o sea por la INFORMACIÓN que los usuarios desean obtener. Esto implica que se debe entrevistar a los usuarios para preguntarles todo lo concerniente a la INFORMACIÓN que necesitan.
unidad #1 diseño de base de datos consideraciones
Consideracion de diseño de datos
Access organiza la información en tablas: listas de filas y columnas que recuerda a una hoja de cálculo o libros contables. En una base de datos simple, es posible que tenga una única tabla. La mayoría de las bases de datos necesita más de uno. Por ejemplo, es posible que tenga una tabla que almacena información sobre productos, otra tabla que almacena información acerca de los pedidos y otra tabla con información acerca de los clientes.
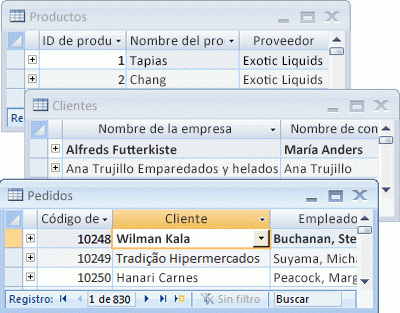
Cada fila se denomina más correctamente un registroy cada columna, un campo. Un registro es una forma lógica y coherente de combinar información sobre algo. Es un campo de un solo elemento de la información: un tipo de elemento que aparece en cada registro. En la tabla productos, por ejemplo, cada fila o registro contiene la información acerca de un producto. Cada columna o el campo contiene algún tipo de información acerca de ese producto, como su nombre o el precio.
base de dato bien diseñada
Determinados principios guían el proceso de diseño de base de datos. El primer principio es que información duplicada (también llamado datos redundantes) es incorrecta, porque residuos espacio y aumenta la probabilidad de errores e incoherencias. El segundo principio es que la exactitud y la integridad de la información importante. Si la base de datos contiene información incorrecta, los informes que extraen información de la base de datos también contener información incorrecta. Como resultado, las decisiones que se basen en dichos informes se luego estar mal informadas.
Un diseño de base de datos buena es, por lo tanto, uno que:
Divide la información en tablas basadas en temas para reducir los datos redundantes.
Proporciona acceso a la información necesaria para unir la información en las tablas según sea necesario.
Ayuda a garantizar la precisión y la integridad de su información.
Admite el procesamiento de datos e informes necesidades.
El proceso de diseño
El proceso de diseño consta de los siguientes pasos:
Determinar el propósito de la base de datos
Esto le ayuda a prepararse para el resto de los pasos.
Buscar y organizar la información necesaria
Recopile todos los tipos de información que desea grabar en la base de datos, como el número de nombre y orden de producto.
Dividir la información en tablas
Dividir los elementos de información en entidades o temas, como productos o pedidos principales. Cada tema se convierte en una tabla.
Convertir los elementos de información en columnas
Decida qué información desea almacenar en cada tabla. Cada elemento se convierte en un campo y se muestra como una columna de la tabla. Por ejemplo, una tabla empleados puede incluir campos como apellido y fecha de contratación.
Especificar claves principales
Elija la clave principal de cada tabla. La clave principal es una columna que se utiliza para identificar inequívocamente cada fila. Un ejemplo podría ser el identificador de producto o Id.
Configurar las relaciones de tabla
Examine cada tabla y decida cómo los datos en una tabla relacionados con los datos en otras tablas. Agregar campos a las tablas o cree nuevas tablas para clarificar las relaciones según sea necesario.
Refinar el diseño
Analizar el diseño de errores. Crear las tablas y agregue algunos registros de datos de ejemplo. Vea si puede obtener los resultados que desee en las tablas. Realizar ajustes en el diseño, según sea necesario.
Aplicar las reglas de normalización
Aplicar las reglas de normalización de datos para ver si las tablas están estructuradas correctamente. Realizar ajustes en las tablas, según sea necesario.


Como crear un blog
Cómo crear un blog
- Accede a Blogger.
- A la izquierda, haz clic en la flecha hacia abajo .
- Haz clic en Nuevo blog.
- Escribe el nombre que quieras darle a tu blog.
- Presiona Siguiente.
- Elige una dirección o URL para el blog
- Haz clic en Guardar.
¿Que es un blog y para que sirve caracteristicas y elementos?

blog
Seguramente habrás escuchado el término “blogueros” o que en algún blog se reveló información importante acerca de un asunto político o de otro aspecto de la vida social. Pero ¿qué es un blog y para qué sirve? En esta lección podrás despejar esas inquietudes.
Un blog es una página web en la que se publican regularmente artículos cortos con contenido actualizado y novedoso sobre temas específicos o libres. Estos artículos se conocen en inglés como "post" o publicaciones en español.
Los artículos de un blog suelen estar acompañados de fotografías, videos, sonidos y hasta de animaciones y gráficas que ilustran mucho mejor el tema tratado. En pocas palabras, un blog es un espacio en internet que puedes usar para expresar tus ideas, intereses, experiencias y opiniones.
Si eres un usuario frecuente de internet, es bastante probable que ya hayas leído el blog de alguien más sin darte cuenta, ya que gran parte de la información que conseguimos en la red está en blogs.
Los blogs iniciaron como espacios en línea donde las personas podían expresar sus opiniones, pensamientos, fotografías e incluso videos. La mayoría de los blogs son escritos por una sola persona y otros son creados en conjunto como las revistas en internet que tienen una gran credibilidad y un enorme número de lectores y seguidores.
Características principales de Blogger:
Creación de múltiples Blogs con un solo registro.
Adición de usuarios para que publiquen Entradas (posts) o administren el Blog.
Capacidad de almacenamiento de archivos de imagenes
Capacidad de almacenamiento de archivos de video
Interfaz en varios idiomas en el modo diseño del Blog.
Etiquetas para las Entradas
Importación automática de entradas y comentarios, provenientes de otros Blogs creados en Blogger.
Exportación automática de la información de un Blog (entradas, etiquetas y archivos) en un archivo XML.
Disponibilidad de Plantillas listas para utilizar.
Posibilidad de agregar al Blog gadgets con diversas funcionalidades.
Diferencia entre Blog & Sitio Web
Recordemos que un “web site” puede tener múltiples paginas. Con la definición previa acerca de qué es un blog y para qué sirve, un sitio puede integrar una pagina online dedicada al blog. En adición, un Blog se diferencia en los siguientes aspectos:
- Blog provee contenido fresquito!: Si señores como el pan recién salido del horno. En cualquier temática un blog publica periódicamente novedades, actualizaciones e información relevante. En contraste un sitio no cambia su contenido muy a menudo.
- Blog permite seducir lectores!: Un blog al ser compartido en redes sociales por ejemplo permite la interacción con los lectores y la discusión permanente. El blog fija una perspectiva o posición que un sitio web difícilmente puede proyectar por la estaticidad de la información.
Ventajas de contar con un Blog
Sea en lo personal o a nivel de negocios, para especificar qué es un blog y para qué sirve, es necesario analizar las ventajas que ofrece:
- Actualizado regularmente: Posibilita mantener a tus lectores o compradores al día respecto a tu marca. Las ideas son cambiantes y en internet se debe proveer la vanguardia/experticia de tu temática en las publicaciones de blog.
- Herramienta de aprendizaje: Un blog por lo general es una pagina online que contiene información relevante o de interés para las personas que navegan en la red.
- Cercanía y confianza a tus lectores: El blog puede consolidar tu conocimiento, experticia o credibilidad promoviendo la interacción con tus contenidos.
- Posiciona tu marca en buscadores:Los buscadores web aman el contenido nuevo, innovador y de valor. El blog es una excelente manera de posicionar tu marca en los resultados de internet (SEO).
- Posibilidad de encontrar clientes:Si quieres emprender, un blog es la manera idónea de consolidar una reputación en la red y darte a conocer de forma independiente.
- Permite ganar dinero: Conseguir que un blog sea rentable requiere de mucha dedicación y constancia en un mundo donde muchos escriben en la red. Al lograrlo muchos querrán publicitar en tu blog.

Suscribirse a:
Comentarios (Atom)
Visitas del Blog
-
 El diagrama de Gantt es una herramienta para planificar y programar tareas a lo largo de un período determinado. Gracias a una fácil...
El diagrama de Gantt es una herramienta para planificar y programar tareas a lo largo de un período determinado. Gracias a una fácil... -
INTRODUCCION Hoy platicaremos un poco de algo de lo que todos escuchan, algunos hablan, pero pocos saben usar, muy pocos en realidad. La te...
-
 Introducción El proceso administrativo en la administración se considera como una actividad compuesta de ciertas sub-actividades que cons...
Introducción El proceso administrativo en la administración se considera como una actividad compuesta de ciertas sub-actividades que cons... -
Eficaces herramientas de Administración de proyecto. Dirigir un proyecto en el entorno de tensión de una organización en constante movimie...
-
En l a teoria de la probabilidad , el valor esperado de una variable aleatoria , intuitivamente, es el valor promedio a largo plazo de l...
-
La integridad referencial es propiedad de la base de datos. La misma significa que la clave externa de una tabla de referencia siempre deb...
-
Un histograma es una representación gráfica de una variable en forma de barras, teniendo en cuenta que la superficie de cada barra es pr...







