1.1 MODELOS DE BASES DE DATOS
Un modelo de datos es básicamente una "descripción" de algo conocido como contenedor de datos (algo en donde se guarda la información), así como de los métodos para almacenar y recuperar información de esos contenedores. Los modelos de datos no son cosas físicas: son abstracciones que permiten la implementación de un sistema eficiente de base de datos; por lo general se refieren a algoritmos, y conceptos matemáticos.
Algunos modelos con frecuencia utilizados en las bases de datos:

En este modelo los datos se organizan en una forma similar a un árbol (visto al revés), en donde un nodo padre de información puede tener varios hijos. El nodo que no tiene padres es llamado raíz, y a los nodos que no tienen hijos se los conoce como hojas.
Las bases de datos jerárquicas son especialmente útiles en el caso de aplicaciones que manejan un gran volumen de información y datos muy compartidos permitiendo crear estructuras estables y de gran rendimiento.
Una de las principales limitaciones de este modelo es su incapacidad de representar eficientemente la redundancia de datos.
Base de datos de red:

Éste es un modelo ligeramente distinto del jerárquico; su diferencia fundamental es la modificación del concepto de nodo: se permite que un mismo nodo tenga varios padres (posibilidad no permitida en el modelo jerárquico).
Fue una gran mejora con respecto al modelo jerárquico, ya que ofrecía una solución eficiente al problema de redundancia de datos; pero, aun así, la dificultad que significa administrar la información en una base de datos de red ha significado que sea un modelo utilizado en su mayoría por programadores más que por usuarios finales.
Bases de datos transaccionales
Son bases de datos cuyo único fin es el envío y recepción de datos a grandes velocidades, estas bases son muy poco comunes y están dirigidas por lo general al entorno de análisis de calidad, datos de producción e industrial, es importante entender que su fin único es recolectar y recuperar los datos a la mayor velocidad posible, por lo tanto la redundancia y duplicación de información no es un problema como con las demás bases de datos, por lo general para poderlas aprovechar al máximo permiten algún tipo de conectividad a bases de datos relacional.
Bases de datos relacionales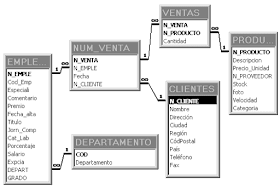
Estés el modelo utilizado en la actualidad para modelar problemas reales y administrar datos dinámica mente. Tras ser postulados sus fundamentos en 1970 por Edgar Frank Codd, de los laboratorios IBM en San José (California), no tardó en consolidarse como un nuevo paradigma en los modelos de base de datos. Su idea fundamental es el uso de "relaciones". Estas relaciones podrían considerarse en forma lógica como conjuntos de datos llamados "tuplas". Pese a que ésta es la teoría de las bases de datos relacionales creadas por Codd, la mayoría de las veces se conceptualiza de una manera más fácil de imaginar. Esto es pensando en cada relación como si fuese una tabla que está compuesta por registros (las filas de una tabla), que representarían las tuplas, y campos (las columnas de una tabla).
En este modelo, el lugar y la forma en que se almacenen los datos no tienen relevancia (a diferencia de otros modelos como el jerárquico y el de red). Esto tiene la considerable ventaja de que es más fácil de entender y de utilizar para un usuario esporádico de la base de datos. La información puede ser recuperada o almacenada mediante "consultas" que ofrecen una amplia flexibilidad y poder para administrar la información.
El lenguaje más habitual para construir las consultas a bases de datos relacionales es SQL, Structured Query Language o Lenguaje Estructurado de Consultas, un estándar implementado por los principales motores o sistemas de gestión de bases de datos relacionales.
1.2 CONSIDERACIONES DE DISEÑO

Una Base de Datos sirve para guardar datos en ella y para procesar dichos datos. El resultado de ese proceso se llama INFORMACIÓN.
DATOS —> PROCESO —> INFORMACIÓN
Los usuarios ingresan los DATOS en las tablas, en los stored procederes y en los triggers se PROCESAN esos datos, y el resultado de ese procesamiento es la INFORMACIÓN que se obtiene.
Para que la INFORMACIÓN sirva debe ser exacta, oportuna y confiable. Esto solamente puede conseguirse si los DATOS introducidos son exactos y si el PROCESO al que son sometidos es correcto. Si cualquiera de ellos (datos o proceso) está mal entonces es seguro que la INFORMACIÓN estará mal.
La introducción de los DATOS corre por cuenta y es responsabilidad de los usuarios.
El PROCESAMIENTO y la INFORMACIÓN corren por cuenta y es responsabilidad del diseñador de la Base de Datos.
Si un DATO es incorrecto, fue mal introducido, parte de la culpa puede ser del usuario y la otra parte de la culpa puede ser del diseñador de la Base de Datos.
Para evitar o al menos disminuir grandemente la posibilidad de que un usuario introduzca datos erróneos el Firebird nos provee de varias herramientas: restricción Foreign Key, restricción Ónique Key, restricción Check, dominios, triggers.
Mediante la restricción Foreign Key nos aseguramos que en una columna solamente se puedan guardar valores que existen en otra tabla. Si no existen en la otra tabla, no se grabarán.
Mediante la restricción Unique Key nos aseguramos que en una columna no haya datos repetidos. Ni duplicados, ni triplicados, ni nada de eso. Solamente datos únicos.
Mediante la restricción Check nos aseguramos que en una columna (o serie de columnas) solamente se puedan introducir valores que cumplen con las condiciones impuestas.
Mediante los dominios nos aseguramos que los valores de una columna sean solamente los permitidos.
Mediante los triggers nos aseguramos que antes de insertar o actualizar una fila los valores de sus columnas sean valores permitidos.
Si los DATOS o el PROCESO son incorrectos entonces lo que se obtiene no sirve, en otras palabras se obtiene basura, porque DATOS correctos utilizados por un PROCESO incorrecto da como resultado basura y DATOS incorrectos utilizados por un PROCESO correcto también dan por resultado basura.
Un “dato” es lo que se guarda, una “información” es lo que se obtiene después de “procesar” a los “datos”.
Siempre por el final, o sea por la INFORMACIÓN que los usuarios desean obtener. Esto implica que se debe entrevistar a los usuarios para preguntarles todo lo concerniente a la INFORMACIÓN que necesitan.










Buen tema para devatir no crees
ResponderEliminar